ScaleOps' new AI Infra Product slashes GPU costs for self-hosted enterprise LLMs by 50% for early adopters


ScaleOps has expanded its cloud resource management platform with a new product aimed at enterprises using self-hosted large language models (LLMs) and GPU-based AI applications.
The AI Infra Product Announced Todayextends the company’s existing automation capabilities to meet the growing need for efficient GPU usage, predictable performance, and reduced operational burden in large-scale AI deployments.
The company says the system is already running in enterprise production environments and delivering big efficiency gains for early adopters, reducing GPU costs by between 50% and 70%, the company said. The company is not disclosing the enterprise pricing for this solution and instead invites interested customers to receive a customized quote based on the size and needs of their business here.
In explaining how the system behaves under heavy loads, Yodar Shafrir, CEO and co-founder of ScaleOps, said in an email to VentureBeat that the platform uses “proactive and reactive mechanisms to handle sudden spikes without impacting performance,” noting that the workload adjustment policy “automatically manages capacity to keep resources available.”
He added that minimizing GPU slowdowns during cold starts was a priority, highlighting that the system “guarantees immediate response when traffic increases,” especially for AI workloads where model load times are significant.
Extending resource automation to AI infrastructure
Companies deploying self-hosted AI models face performance variations, long load times, and persistent underutilization of GPU resources. ScaleOps positioned the new AI Infra product as a direct response to these problems.
The platform allocates and scales GPU resources in real time and adapts to changes in traffic demand without requiring changes to existing model deployment pipelines or application code.
According to ScaleOps, the system manages production environments for organizations such as Wiz, DocuSign, Rubrik, Coupa, Alkami, Vantor, Grubhub, Island, Chewy and several Fortune 500 companies.
The AI Infra product introduces workload-aware scaling policies that proactively and reactively adjust capacity to maintain performance during peak demand. The company stated that this policy reduces cold start delays associated with loading large AI models, improving responsiveness when traffic increases.
Technical integration and platform compatibility
The product is designed for compatibility with common enterprise infrastructure patterns. It works on all Kubernetes distributions, major cloud platforms, on-premises data centers and air-gapped environments. ScaleOps emphasized that the implementation will not require any code changes, infrastructure rewrites, or adjustments to existing manifests.
Shafrir said the platform “seamlessly integrates into existing model deployment pipelines without the need for any code or infrastructure changes,” adding that teams can immediately start optimizing with their existing GitOps, CI/CD, monitoring and deployment tools.
Shafrir also discussed how automation works with existing systems. He said the platform works without disrupting workflows or creating conflicts with custom scheduling or scaling logic. He explains that the system “does not change the manifests or deployment logic” and instead enhances schedulers, autoscalers, and custom policies by incorporating real-time operational context while respecting existing configuration boundaries.
Performance, visibility and user control
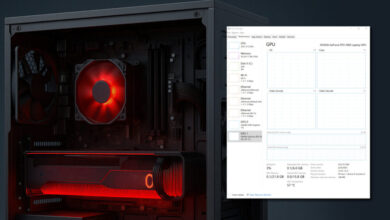
The platform provides complete visibility into GPU usage, model behavior, performance metrics, and scaling decisions at multiple levels including pods, workloads, nodes, and clusters. Although the system applies default workload scaling policies, ScaleOps noted that engineering teams retain the ability to tune these policies as needed.
In practice, the company aims to reduce or eliminate the manual tuning that DevOps and AIOps teams typically perform to manage AI workloads. The installation is intended to require minimal effort, described by ScaleOps as a two-minute process using a single rudder flag, after which optimization can be enabled through a single action.
Cost savings and case studies for enterprises
ScaleOps reported that early implementations of the AI Infra product have delivered GPU cost savings of 50-70% in customer environments. The company cited two examples:
-
A large creative software company operating thousands of GPUs had an average utilization of 20% before adopting ScaleOps. The product increased utilization, consolidated underutilized capacity, and enabled GPU node reductions. These changes have reduced overall GPU spending by more than half. The company also reported a 35% reduction in latency for key workloads.
-
A global gaming company used the platform to optimize a dynamic LLM workload on hundreds of GPUs. According to ScaleOps, the product increased usage by a factor of seven while maintaining service-level performance. The client expected annual savings of $1.4 million from this workload alone.
ScaleOps stated that the expected GPU savings typically exceed the costs of adopting and operating the platform, and that customers with limited infrastructure budgets have reported a quick return on their investment.
Industry context and business perspective
The rapid adoption of self-hosted AI models has created new operational challenges for companies, especially around GPU efficiency and the complexity of managing large-scale workloads. Shafrir described the broader landscape as one in which “cloud-native AI infrastructure is reaching a breaking point.”
“Cloud-native architectures unlocked great flexibility and control, but also introduced a new level of complexity,” he said in the announcement. “Managing GPU resources at scale has become chaotic: waste, performance issues, and skyrocketing costs are now the norm. The ScaleOps platform is built to solve this. It delivers the complete solution for managing and optimizing GPU resources in cloud-native environments, allowing companies to run LLMs and AI applications efficiently and cost-effectively while improving performance.”
Shafrir added that the product brings together the full set of cloud resource management features needed to manage diverse workloads at scale. The company positioned the platform as a holistic system for continuous, automated optimization.
A uniform approach for the future
With the addition of the AI Infra Product, ScaleOps aims to create a unified approach to GPU and AI workload management that integrates with existing enterprise infrastructure.
The platform’s early performance metrics and reported cost savings suggest a focus on measurable efficiencies within the growing ecosystem of self-hosted AI deployments.