Mining Government Gold: Big Data Opportunities in the $68 Billion Unclaimed Property Market
Market Opportunity Analysis
In the public sector, few data troves are so large and under -utilized as non -reclaimed ownership records. In total, the United States maintains $ 68+ billion in sleeping assets spread over 50+ state principles, quasi-governmental offices and affiliated managers. The result is a vast constellation of searchable grandbooks: names of the owner, most recently known addresses, financial institutions, amounts, date stamps, asset categories and disposition codes. For data scientists, this seems like a long tail of messy but valuable signals. For product builders it is a market that naturally rewards high -quality integration, standardization, identity resolution and user experience. And for investors it is a space with clear paths of income: lead generation for power repair services, premium matching accuracy for professionals, data products for compliance teams and embedded claims for fintechs and financial advisers.
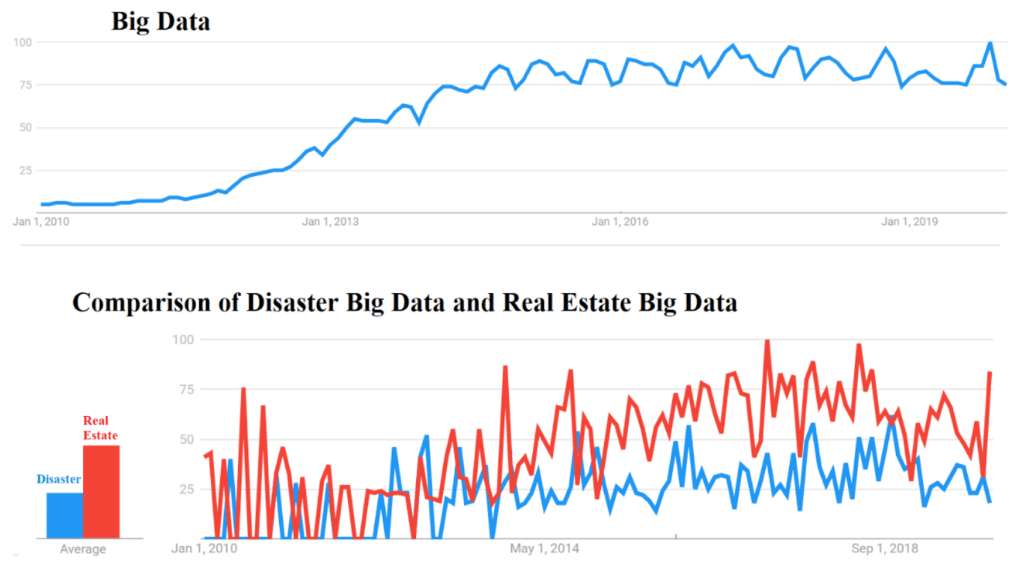
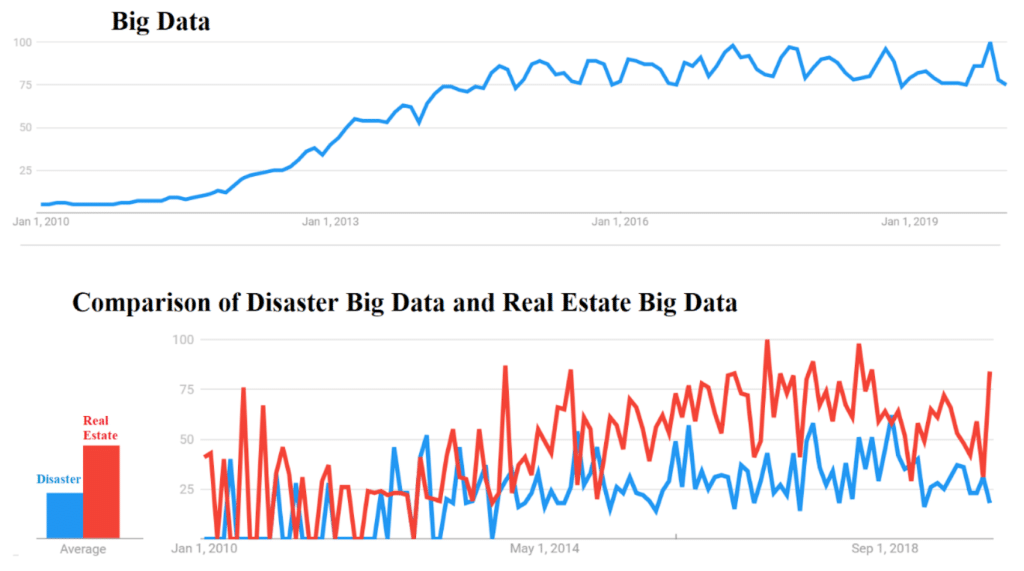
Figure. Increasing Big Data Momentum in the past decade, with domain volatility (disaster versus real estate) underlines why $ 68 billion non -claimed real estate analyzes are ripe for targeted insights.
The chance includes various industries. Fintech can proactive warnings within Bank apps surfaces when users are likely to be linked to dormant assets. Civic Tech can build public benefit tools that increase the claim rates and at the same time lower the administrative friction. Insurtech and asset managers can reduce Escheatment by detecting risky accounts early. Even marketing and analysis teams can use these patterns to gain a deeper insight into mobility, life events and demographic behavior associated with leaving assets and recovery. Platforms such as Claim informed Point out a pragmatic model: collect millions of records, unite schedules and deliver searches of consumer quality that convert rough led by clear answers.
Data integration technical challenges
Schedule -standardization. Each state speaks a different dialect. Field names vary, type drift and optional fields spread. One data set can split first and surnames; Another can store a single field with a free text. Address structures reflect old forms. A viable platform must assign dozens of source schedules to a canonical model, with robust treatment for zero, multiple owners, business entities and historical revisions.
API restrictions. Some states offer tariff-restricted APIs with auth tests and variable paging; Others have Brosse endpoints that are sensitive to maintenance windows. Various offer only search interfaces with limited export functions. Orchestration must take into account back-off, Jitter, token renewal and automatic recovery of partial pulls.
Variations for data quality. Expect typing errors, old addresses, truncated names and inconsistent date layouts. Proven pipelines tend to be on deterministic rules plus probabilistic matching to reconcile duplicates, to merge together in the vicinity of competitions and to score trust per candidate.
Real -time processing. Keeping the data up to date is not -trivial because states update on different cadence. Effective systems schedule Incremental pulls, difference the new against the warehouse and distributes Deltas via electricity indexes. Platforms such as Claim Notify have adopted resilient intake and processing of change data to keep search results fresh without hammering fragile sources.
Machine Learning -Applications
Pattern recognition. Non -controlled methods can cluster the signatures of the abandonment: changes in the employer, the intermediate state movements or bank stall. These clusters help predict where not -eclaimed assets will arise and which cohorts they will most likely recover.
Fraud Detection. Supervised classifications, anomalo detection and graph dialyses can mark suspicious cliffp patterns, such as repeated attempts about many small accounts or identity characteristics that do not have non-controls. Risk scores roustate risky cases in manual assessment without humiliating fair user experience.
Predictive modeling. Gradient stimulation or generalized additive models can estimate the chance that a match is real and that a user will complete a claim once it has started. Prioritization improves when the model links data signals to behavioral stemetry from the search interface.
Natural language processing. Fuzzy name matching benefits of phonetic codes, transliteration support, nickname dictionaries and address normalization. NLP also helps with the dedaping of business entities, parsing line noise in legacy fields and the coordination of variant spellings.
Behavioral analysis. Funnel analysis quantifies where users drop off. If most uploads leave documentation, the solution is UX and education. If the problem is understanding, in-flow guidelines reduce confusion. This is where platforms such as Claim informed Change ML Insight to UX Impact.
ROI and investment analysis
The economy is attractive. On the cost side, the technical investment flows to data connectors, schemamapping, Ml -pipelinesand identity resolution. On the income side include viable models Premium Search for power users, B2B access for professionals, embedded recovery services and partner integrations. Governments save on support costs when claimants serve self -service successfully. Financial advisers and fintechs increase customer satisfaction by helping customers reunite with assets. Venture capital interest follows where there is recurring value and defensible data canals. With millions of records and frequent updates, network and data effects come to teams that constantly improve the corresponding accuracy and UX.
Future applications
Expansion to adjacent verticals. Auctions of real estate tax, reimbursements from the court-conducted conductor, distributions in the class action and non-adapted wage controls share similar data DNA. The same ETL and ML stack can extend horizontally.
Blockchain for origin. Inventional audit paths can improve the chains for claims, but interoperability and privacy restrictions must first be resolved. Expect hybrid models that anchor evidence and at the same time keep PII off-chain.
AI-driven reports. With the permission of users, models can check life events that correlate with Escheatment Risk and proactively inform users before their assets are sleeping.
Fertech. Banks and wealth platforms can add a white-label search that checks for non-raised assets during onboarding or annual reviews. This positions recovery as part of a holistic approach to financial health.
Call for action
The Playbook is clear to data leaders: build a robust integration layer, treatment of data quality as a product and links ML with humane UX. For policymakers and partners, work together with private platforms that can change spread grandbooks into results. If you want a working reference architecture to help people find money that they owe, investigate how claims claim these ideas to a consumer scale.




