MINT-1T: Scaling Open-Source Multimodal Data by 10x

Training frontier large multimodal models (LMMs) requires large-scale datasets with interleaved sequences of images and text in free form. Although open-source LMMs have evolved rapidly, there is still a major lack of multi-modal interleaved datasets at scale which are open-sourced. The importance of these datasets cannot be overstated, as they form the foundation for creating advanced AI systems capable of understanding and generating content across different modalities. Without a sufficient supply of comprehensive, interleaved datasets, the potential for developing more sophisticated and capable LMMs is significantly hindered. These datasets enable models to learn from a diverse range of inputs, making them more versatile and effective in various applications. Furthermore, the scarcity of such datasets poses a challenge to the open-source community, which relies on shared resources to drive innovation and collaboration.
Open-source LMMs have made significant strides in recent years, but their growth is hampered by the limited availability of large-scale, interleaved datasets. To overcome this obstacle, concerted efforts are needed to curate, annotate, and release more comprehensive datasets that can support the ongoing development and refinement of multimodal models. In addition, the creation and dissemination of these datasets involve overcoming several technical and logistical hurdles. Data collection must be extensive and representative of the diverse contexts in which LMMs will be deployed. Annotation requires careful consideration to ensure that the interleaved sequences of images and text are aligned in a manner that enhances the model’s learning capabilities. Moreover, ensuring the datasets are open-source entails addressing legal and ethical considerations related to data privacy and usage rights. Expanding the availability of high-quality, large-scale multimodal interleaved datasets is essential for the future of AI research and development. By addressing the current scarcity, the AI community can foster greater innovation and collaboration, leading to the creation of more powerful and versatile LMMs capable of tackling complex, real-world problems.
Building on that note, MINT-1T, the largest and most diverse multimodal interleaved open-source dataset to date. MINT-1T: A 10x larger scale, including one trillion text tokens & 3.4 billion images than existing open-source datasets. The MINT-1T dataset also introduces never-exposed sources such as PDF files, ArXiv papers. Since multimodal interleaved datasets do not scale easily, it is important that the MINT-1T dataset shares the data curation process so others can also perform experiments on such information-rich variants. The MINT-1T dataset demonstrates that its method; LM models trained on MINT-1T are competitive (albeit somewhat) to previous state-of-the-art OBELICS.
MINT-1T: A Multimodal Dataset with One Trillion Tokens
Large open-source pre-training datasets have been pivotal for the research community in exploring data engineering and training transparent, open-source models. In the text domain, early works such as C4 and The Pile played crucial roles in enabling the community to train the first set of open-source large language models like GPT-J, GPT-Neo, and others. These foundational efforts also paved the way for subsequent improvements in data filtering methods and scaling. Similarly, in the image-text space, large-scale open-source datasets have spurred innovations in better data curation methods, such as Data filtering networks and T-MARS. There is a noticeable shift from frontier labs towards training large multimodal models (LMMs) that require extensive multimodal interleaved datasets comprising free-form sequences of images and text. As the capabilities of frontier models advance rapidly, a significant gap is emerging in the multimodal training data between closed- and open-source models. Current open-source multimodal interleaved datasets are smaller and less diverse than their text-only counterparts, being sourced primarily from HTML documents, which limits the breadth and variety of data. This limitation impedes the development of robust open-source LMMs and creates a disparity between the capabilities of open- and closed-source models.
To address this gap, MINT-1T was created as the largest and most diverse open-source multimodal interleaved dataset to date. MINT-1T contains a total of one trillion text tokens and three billion images, sourced from diverse origins such as HTML, PDFs, and ArXiv. Before MINT-1T, the largest open-source dataset in this area was OBELICS, which included 115 billion text tokens and 353 million images, all sourced from HTML.

The contributions of MINT-1T are as follows:
- Data Engineering: Scaling this multimodal interleaved data presents more of an engineering challenge than building either text-only or image-text pair datasets. Handling much larger document sizes and preserving the original ordering of images and text is crucial.
- Diversity: MINT-1T is the first in the multimodal interleaved space to gather high-quality multimodal documents at large scales from sources like CommonCrawl PDFs and ArXiv.
- Model Experiments: Experiments show that LMMs trained on MINT-1T not only match but potentially surpass the performance of models trained on the best existing open-source dataset, OBELICS, while offering a tenfold increase in scale.
MINT-1T: Constructing the Dataset
MINT-1T curates a large-scale open-source dataset that utilizes more diverse sources of interleaved documents, such as PDFs and ArXiv papers. This section details MINT-1T’s methods for sourcing multimodal documents, filtering low-quality content, deduplicating data, and removing not safe for work or NSFW and undesirable material. The final dataset comprises 922 billion (B) HTML tokens, 106B PDF tokens, and 9B ArXiv tokens.
Sourcing Large Quantities of Multimodal Documents
HTML Pipeline
MINT-1T follows OBELICS’s method for extracting interleaved multimodal documents from CommonCrawl WARC files by parsing each WARC entry’s DOM tree. While OBELICS only processed documents from February 2020 to February 2023 CommonCrawl dumps, MINT-1T has expanded the document pool to include HTML documents from May 2017 to April 2024 (with full dumps from October 2018 to April 2024 and partial dumps from earlier years). Similar to OBELICS, MINT-1T filters out documents containing no images, more than thirty images, or any images with URLs that include inappropriate substrings such as logo, avatar, porn, and xxx.
PDF Pipeline
MINT-1T sources PDF documents from CommonCrawl WAT files from February 2023 to April 2024 dumps. Initially, all PDF links are extracted from these dumps. MINT-1T then attempts to download and read PDFs using PyMuPDF, discarding PDFs over 50MB (likely containing large images) and those over 50 pages long. Pages without text are excluded, and a reading order is established for the remaining pages. Reading order is determined by finding the bounding box of all text blocks on a page, clustering the blocks based on columns, and ordering them from top left to bottom right. Images are integrated into the sequence based on their proximity to text blocks on the same page.

ArXiv Pipeline
MINT-1T builds ArXiv interleaved documents from LaTeX source code using TexSoup to find figure tags and interleave images with the paper text. For multi-file papers, MINT-1T identifies the main Tex file and replaces input tags with the contents of its files. The LaTeX code is cleaned up by removing imports, bibliography, tables, and citation tags. Since ArXiv is already a highly curated data source, no additional filtering and deduplication are performed.
Text Quality Filtering
MINT-1T avoids using model-based heuristics for text filtering, following practices established by RefinedWeb, Dolma, and FineWeb. Initially, non-English documents are eliminated using Fasttext’s language identification model (with a confidence threshold of 0.65). Documents with URLs containing NSFW substrings are also removed to exclude pornographic and undesirable content. Text filtering methods from RefinedWeb are applied, specifically removing documents with excessive duplicate n-grams or those identified as low quality using MassiveText rules.
Image Filtering
After curating PDFs and HTML files, MINT-1T attempts to download all image URLs in the HTML dataset, discarding non-retrievable links and removing documents with no valid image links. Images smaller than 150 pixels are discarded to avoid noisy images such as logos and icons, and images larger than 20,000 pixels are also removed as they usually correspond to off-topic images. For HTML documents, images with an aspect ratio greater than two are removed to filter out low-quality images such as advertisement banners. For PDFs, the threshold is adjusted to three to preserve scientific figures and tables.

The above figure represents how MINT-1T uniquely includes data from PDFs and ArXiv documents beyond HTML sources.
Safety Filtering
- NSFW Image Filtering: MINT-1T applies an NSFW image detector to all images in the dataset. If a document contains a single NSFW image, the entire document is discarded.
- Personally Identifiable Information Removal: To mitigate the risk of personal data leakage, email addresses and IP addresses in the text data are anonymized. Emails are replaced with templates such as “[email protected]” and IPs with randomly generated non-functional IPs.
Deduplication
MINT-1T performs paragraph and document text deduplication within each CommonCrawl snapshot and image deduplication to remove repetitive, uninformative images such as icons and logos. All deduplication steps are conducted separately for each data source.
Paragraph and Document Deduplication
Following Dolma’s methodology, MINT-1T uses a Bloom Filter for efficient text deduplication, setting the false positive rate to 0.01 and deduplicating 13-gram paragraphs (indicated through double newline delimiters) from each document. If more than 80% of a document’s paragraphs are duplicates, the entire document is discarded.
Removing Common Boilerplate Text
After paragraph deduplication, MINT-1T removes short common boilerplate sentences in HTML documents, such as “Skip to content” or “Blog Archive.” This is done by running exact paragraph deduplication on 2% of each CommonCrawl snapshot, in line with CCNet practices, ensuring mostly the removal of common boilerplate text.

The above figure demonstrates the filtering process for MINT-1T, and shows how tokens are removed throughout the data pipeline for HTML, PDFs, and ArXiv papers.
Image Deduplication
Within each CommonCrawl snapshot, MINT-1T removes frequently occurring images based on SHA256 hashes. Rather than strict deduplication, only images that appear more than ten times within a snapshot are removed, following Multimodal-C4 practices. Consistent with OBELICS, repeated images within a single document are removed, keeping only the first occurrence.
Infrastructure
Throughout the data processing, MINT-1T had access to an average of 2,350 CPU cores from a mix of 190-processor and 90-processor nodes. In total, approximately 4.2 million CPU hours were used to build this dataset.
Comparing Document Composition in MINT-1T with OBELICS
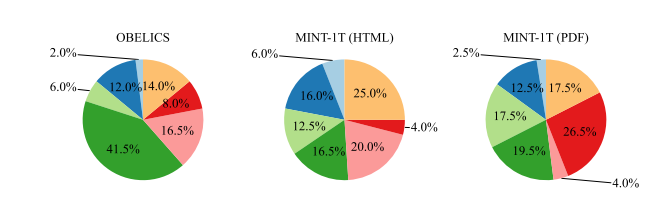
In evaluating the composition of interleaved datasets, two key characteristics are examined: the distribution of text tokens per document and the number of images per document. For this analysis, 50,000 documents were randomly sampled from both OBELICS and each data source in MINT-1T. GPT-2’s tokenizer was used to calculate the number of text tokens. Outliers were removed by excluding documents that fell outside the 1.5 interquartile range for the number of text tokens and images. As shown in the following figure, the HTML subset of MINT-1T aligns closely with the token distribution seen in OBELICS. However, documents sourced from PDFs and ArXiv tend to be longer than HTML documents on average, highlighting the benefits of sourcing data from diverse sources. Figure 5 examines the image density across all documents, revealing that PDFs and ArXiv documents contain more images compared to HTML documents, with ArXiv samples being the most image-dense.

How Do Different Data Sources Improve Document Diversity?
An important motivation for expanding the pool of multimodal documents beyond HTML is the improvement of domain coverage. To quantify the diversity and depth of this coverage, a Latent Dirichlet Allocation (LDA) model was trained on 100,000 documents sampled from the OBELICS dataset, the HTML subset of MINT-1T, and the PDF subset (excluding ArXiv) from MINT-1T to get 200 topics. GPT-4 was then used to classify the set of words to identify the dominant domains – such as Health & Medicine, Science, Business, Humanities, History, etc. – based on MMMU domains. The analysis reveals distinct trends in domain distribution:
- OBELICS: This dataset shows a pronounced concentration in “Humanities and Social Sciences”. This may be attributed to its data construction process, which involves filtering out documents that do not resemble Wikipedia articles, thus potentially altering the distribution to more general knowledge and humanities-focused content.
- MINT-1T’s HTML Subset: In contrast to OBELICS, the HTML subset of MINT-1T is not strongly biased towards any specific domain, suggesting a broader and more balanced domain representation.
- MINT-1T’s PDF Subset: There is a higher proportion of “Science and Technology” documents within the PDF documents of MINT-1T. This trend is likely due to the nature of scientific communication, where PDFs are the preferred format for sharing detailed research papers and technical reports.
MINT-1T: Results and Experiments
For all experiments, MINT-1T trains the model on 50% image-text captioning batches and 50% multimodal interleaved batches. A maximum of 2048 multimodal tokens is sampled from each interleaved document and 340 tokens from each image-text sample. Similar to Flamingo, an “end” token is added to indicate the end of an adjacent image-text sequence. During training, 50% of single-image interleaved documents are randomly dropped to upsample multi-image documents. The image-text dataset is composed of a mixture of internally curated caption datasets.The model’s capability to reason about multimodal interleaved sequences is assessed through its in-context learning abilities and multi-image reasoning performance.
The above figure illustrates the percentage of documents from each domain in MMMU for OBELICS and subsets of MINT-1T.
In-Context Learning: The models are evaluated on four-shot and eight-shot in-context learning performance on various captioning benchmarks (COCO (Karpathy test) and TextCaps (validation)) and visual question answering datasets (VQAv2 (validation), OK-VQA (validation), TextVQA (validation), and VizWiz (validation)). Demonstrations are randomly sampled from the training set. Scores are averaged over multiple evaluation runs, with randomized demonstrations to account for sensitivity to chosen prompts. Different prompts are ablated for each task to select the best performing ones.
Multi-Image Reasoning: Models are evaluated on MMMU (containing both single and multi-image questions) and Mantis-Eval (all multi-image questions) to probe multi-image reasoning abilities beyond in-context learning evaluations.
Training on HTML Documents
Initially, the HTML portion of MINT-1T is compared to OBELICS, as OBELICS is the previous leading interleaved dataset, also curated from HTML documents. Two models are trained on the HTML portions of MINT-1T and OBELICS for a total of 10B multimodal tokens. Their in-context learning performance is assessed. The following table presents the 4-shot and 8-shot performance on common benchmarks; the model trained on MINT-1T HTML documents performs better than OBELICS on VQA tasks but worse on captioning benchmarks. On average, OBELICS performs slightly better than MINT-1T (HTML).

Adding PDF and ArXiv Documents
Subsequently, training is conducted on MINT-1T’s full data sources, with a mixture of HTML, PDF, and ArXiv documents. The interleaved documents are sampled with 50% from HTML, 45% from PDFs, and 5% from ArXiv. The model is trained for a total of 10B multimodal tokens. As seen in the above table, the model trained on the full MINT-1T data mixture outperforms OBELICS and MINT-1T (HTML) on most in-context learning benchmarks. On more complex multimodal reasoning benchmarks, the MINT-1T model outperforms OBELICS on MMMU but performs worse on Mantis-Eval.
Fine-Grained Trends
How Does In-Context Learning Performance Scale with Demonstrations?
The in-context learning performance is evaluated when prompted with one to eight demonstrations. A single trial per shot count is run for each evaluation benchmark. As seen in the following figure, the model trained on MINT-1T outperforms the model trained on the HTML subset of MINT-1T and OBELICS across all shots. The MINT-1T (HTML) model performs slightly worse than OBELICS.

Performance on Captioning and Visual Question Answering Tasks
The following figure presents the average in-context learning performance on captioning and visual question answering (VQA) benchmarks. OBELICS outperforms all MINT-1T variants on four-shot captioning benchmarks and performs slightly worse compared to MINT-1T on eight-shot captioning. However, MINT-1T significantly outperforms both baselines on VQA benchmarks. MINT-1T (HTML) also outperforms OBELICS on VQA tasks.
Performance on Different Domains
Including diverse domains in MINT-1T is aimed at improving model generalization. The figure earlier breaks down performance on MMMU for each domain. Except for the Business domain, MINT-1T outperforms OBELICS and MINT-1T (HTML). The performance increase in Science and Technology domains for MINT-1T is attributed to the prevalence of these domains in ArXiv and PDF documents.
Final Thoughts
In this article we have talked about MINT-1T, the largest and most diverse multimodal interleaved open-source dataset to date. MINT-1T: A 10x larger scale, including one trillion text tokens & 3.4 billion images than existing open-source datasets. The MINT-1T dataset also introduces never-exposed sources such as PDF files, ArXiv papers. Since multimodal interleaved datasets do not scale easily, it is important that the MINT-1T dataset shares the data curation process so others can also perform experiments on such information-rich variants. The MINT-1T dataset demonstrates that its method; LM models trained on MINT-1T are competitive (albeit somewhat) to previous state-of-the-art OBELICS.





