Meta’s new world model lets robots manipulate objects in environments they’ve never encountered before
Become a member of the event that is trusted by business leaders for almost two decades. VB Transform brings together the people who build the real Enterprise AI strategy. Leather
Although large language models (LLMs) have the text (and other modalities to a certain extent), they miss the physical “common sense” to work in dynamic, real environments. This has limited the use of AI in areas such as production and logistics, where understanding the cause and effect is crucial.
Meta’s newest model, V-Jepa 2Take a step in the direction of bridging this gap by learning a world model from video and physical interactions.
V-Jepa 2 can help create AI applications for which predicting results and planning actions in unpredictable environments with many edge cases must be predicted. This approach can offer a clear path to more capable robots and advanced automation in physical environments.
How a ‘world model’ learns to plan
People develop physical intuition early in life by observing their environment. If you see a ball thrown, you will instinctively know the process and you can predict where it will land. V-Jepa 2 learns a similar ‘world model’, which is the internal simulation of an AI system of how the physical world works.
The model is based on three core possibilities that are essential for company applications: understanding what is happening in a scene, predicting how the scene will change based on an action and plan a series of actions to achieve a specific goal. Like Meta are in blogHis “long-term vision is that world models will enable AI agents to plan and reason in the physical world.”
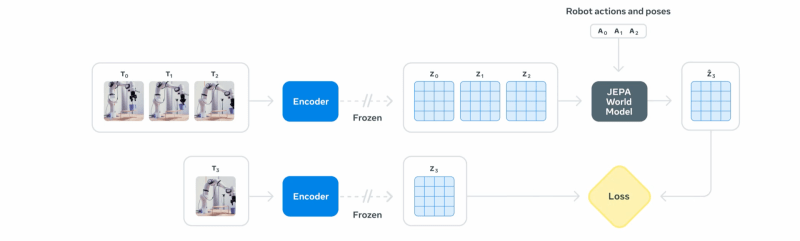
The architecture of the model, the Video Joint Embedding Predictive Architecture (V-Jepa), consists of two important parts. An “encoder” watches a video clip and condenses it in a compact numeric summary, known as an embedding. This embedding records the essential information about the objects and their relationships in the scene. A second component, the ‘predictor’, then takes this summary and imagines how the scene will evolve, which generates a prediction of what the next summary will look like.

This architecture is the latest evolution of the Jepa framework, which was first applied to images with I-Jepa and is now improving on video, which shows a consistent approach to building world models.
In contrast to generative AI models that try to predict the exact color of each pixel in a future frame-a computational intensive task-work-working V-Jepa 2 in an abstract space. It focuses on predicting the characteristics at a high level of a scene, such as the position and process of an object, instead of the texture or background details, making it much more efficient than other larger models with only 1.2 billion parameters
This translates into lower calculation costs and makes it more suitable for implementation in real-world settings.
Learning from observation and action
V-Jepa 2 is trained in two phases. Firstly, it builds up its fundamental understanding of physics through self-entry-school learning, whereby it is viewed more than a million hours of non-labeled internet videos. By simply observing how objects move and work on each other, it develops a world model without human without human guidance.
In the second phase, this pre -trained model is refined on a small, specialized dataset. By processing only 62 hours of video with a robot transport tasks, together with the corresponding control assignments, V-Jepa learns to connect 2 specific actions with their physical results. This results in a model that can plan and control actions in the real world.

This two-stage training makes a critical opportunity for Real-World Automatisering: zero-shot robot planning. A robot powered by V-Jepa 2 can be implemented in a new environment and successfully manipulate objects that it has never been found before, without having to retrainage for that specific institution.
This is an important progress compared to earlier models that require training data of the requirement precisely Robot and surroundings where they would operate. The model was trained on an open-source dataset and then successfully implemented on various robots in Meta’s laboratories.
For example, to complete a task, such as picking up an object, the robot, for example, gets a target of the desired result. It then uses the V-Jepa 2 predictor to simulate a series of possible following movements internally. It scores any imagined action based on how close it comes to the goal, the best rated action carries out and repeats the process until the task is completed.
With the help of this method, the model reached the success rate between 65% and 80% on pick-and-place tasks with unknown objects in new institutions.
Real impact of physical reasoning
This ability to plan and act in new situations has direct implications for business activities. In Logistics and Production, the more adjustable robots makes it possible to process variations in products and warehouse layouts without extensive reprogramming. This can be especially useful, because companies investigate the use of humanoid robots in factories and assembly lines.
The same world model can feed very realistic digital twins, allowing companies to simulate new processes or train other AIs in a physically accurate virtual environment. In industrial environments, a model can follow VideoFeeds of machines and, based on the learned understanding of physics, security problems and failures before they happen.
This research is an important step in the direction of what Meta calls ‘Advanced Machine Intelligence (AMI)’, where AI systems ‘can learn about the world like people do, plan how they can perform unknown tasks and adapt efficiently to the ever-changing world around us.’
Meta has released the model and its training code and hopes “to build a broad community around this study, stimulating progress in the direction of our ultimate goal of developing world models that can transform the way AI deals with the physical world.”
What it means for technical decision makers of companies
V-Jepa 2 moves robotics closer to the software-defined model that cloud teams are already recognizing: pre-train once, deploying everywhere. Because the model learns general physics from the public video and only needs a few dozen task -specific images, companies can reduce the data collection cycle that usually drags pilot projects down. In practical terms you can prototype from a pick-and-place robot on an affordable desktop arm, then roll the same policy to an industrial rig on the factory floor without collecting thousands of new samples or writing adapted movement scripts.
Lower training Overhead reforms the cost comparison. With 1.2 billion parameters, V-Jepa 2 fits comfortably on a single high-quality GPU and its abstract prediction goals further reduce the inference loading. That is why teams can perform a closed loop check on the prem or on the edge, thereby avoid cloud charts and compliance headache supplied with streaming video outside the factory. Budget that once went to massive calculation clusters can, instead, finance extra sensors, redundancy or faster iteration cycles.
Source link