Nearly 80% of Training Datasets May Be a Legal Hazard for Enterprise AI

Een recent artikel van LG AI -onderzoek suggereert dat zogenaamd ‘open’ datasets die worden gebruikt voor het trainen van AI -modellen een vals gevoel van veiligheid kunnen bieden – het vinden van dat bijna vier van de vijf AI -gegevenssets die zijn gelabeld als ‘commercieel bruikbare’ eigenlijk verborgen juridische risico’s bevatten.
Dergelijke risico’s variëren van de opname van niet bekendgemaakt auteursrechtelijk beschermd materiaal tot beperkende licentievoorwaarden die diep in de afhankelijkheden van een dataset zijn begraven. Als de bevindingen van de krant nauwkeurig zijn, moeten bedrijven die op openbare datasets vertrouwen mogelijk hun huidige AI -pijpleidingen heroverwegen of stroomafwaarts risico lopen.
De onderzoekers stellen een radicale en potentieel controversieel Oplossing: AI-gebaseerde compliance-agenten die in staat zijn om datasetgeschiedenis sneller en nauwkeuriger te scannen en te controleren dan menselijke advocaten.
De krant stelt:
‘Dit artikel pleit voor dat het juridische risico van AI-trainingsdatasets niet alleen kan worden bepaald door licentievoorwaarden op oppervlakniveau te bekijken; Een grondige, end-to-end analyse van datasetherverdeling is essentieel voor het waarborgen van naleving.
‘Aangezien een dergelijke analyse buiten de menselijke capaciteiten komt vanwege de complexiteit en schaal, kunnen AI -agenten deze kloof overbruggen door deze met meer snelheid en nauwkeurigheid te voeren. Zonder automatisering blijven kritische juridische risico’s grotendeels niet onderzocht, waardoor ethische AI -ontwikkeling en de therapietrouw in gevaar komen.
‘We dringen er bij de AI-onderzoeksgemeenschap op aan om end-to-end juridische analyse te erkennen als een fundamentele vereiste en AI-aangedreven benaderingen aan te nemen als het haalbare pad naar schaalbare dataset-naleving.’
Bij het onderzoeken van 2.852 populaire datasets die commercieel bruikbaar leken op basis van hun individuele licenties, bleek uit het geautomatiseerde systeem van de onderzoekers dat slechts 605 (ongeveer 21%) daadwerkelijk wettelijk veilig was voor commercialisering zodra al hun componenten en afhankelijkheden waren getraceerd
De nieuw papier is getiteld Vertrouw geen licenties die u ziet-de naleving van de gegevensset vereist een massale schaal AI-aangedreven levenscyclus tracingen komt van acht onderzoekers van LG AI Research.
Rechten en fouten
De auteurs markeren de uitdagingen Geconfronteerd door bedrijven die doorgaan met AI -ontwikkeling in een steeds onzekerder juridisch landschap – omdat de voormalige academische ‘fair use’ -mentaliteit rond datasettraining plaats maakt voor een gebroken omgeving waar juridische bescherming onduidelijk is en veilige haven niet langer wordt gegarandeerd.
Als een publicatie opgemerkt Onlangs worden bedrijven steeds defensiever over de bronnen van hun trainingsgegevens. Auteur Adam Buick Reacties*:
‘[While] OpenAI heeft de belangrijkste gegevensbronnen voor GPT-3 bekendgemaakt, waarbij de paper GPT-4 introduceerde onthuld Alleen dat de gegevens waarop het model was getraind, een combinatie waren van ‘openbaar beschikbare gegevens (zoals internetgegevens) en gegevens die zijn gelicentieerd door externe providers’.
‘De motivaties achter deze stap weg van transparantie zijn niet in een bepaald detail gearticuleerd door AI -ontwikkelaars, die in veel gevallen helemaal geen verklaring hebben gegeven.
‘Van zijn kant rechtvaardigde Openai zijn beslissing om geen verdere details over GPT-4 vrij te geven op basis van zorgen over’ het concurrentielandschap en de veiligheidsimplicaties van grootschalige modellen ‘, zonder verdere uitleg in het rapport.’
Transparantie kan een oneerlijke term zijn – of gewoon een verkeerde; Het vlaggenschip van Adobe Firefly bijvoorbeeld, getraind op voorraadgegevens die Adobe de rechten had om te exploiteren, vermoedelijk aangeboden klanten over de wettigheid van de wettigheid van hun gebruik van het systeem. Later, wat er zijn bewijsmateriaal naar voren gekomen dat de Firefly -gegevenspot ‘verrijkt’ was geworden met mogelijk auteursrechtelijk beschermde gegevens van andere platforms.
Zoals we eerder deze week hebben besproken, zijn er groeiende initiatieven die zijn ontworpen om licentie -naleving in datasets te waarborgen, waaronder een die alleen YouTube -video’s zal schrapen met flexibele Creative Commons -licenties.
Het probleem is dat de licenties op zichzelf onjuist kunnen zijn of fout kunnen worden verleend, zoals het nieuwe onderzoek lijkt aan te geven.
Open source datasets onderzoeken
Het is moeilijk om een evaluatiesysteem te ontwikkelen, zoals de nexus van de auteurs wanneer de context constant verschuift. Daarom stelt de paper dat het Nexus Data Compliance Framework -systeem gebaseerd is op ‘verschillende precedenten en juridische gronden op dit moment in de tijd’.
Nexus gebruikt een AI-aangedreven agent genaamd Autocolliantie voor geautomatiseerde gegevenscompliantie. Autocompliance bestaat uit drie belangrijke modules: een navigatiemodule voor webverkenning; een vraag-antwoord (QA) module voor informatie-extractie; en een scoringsmodule voor juridische risicobeoordeling.
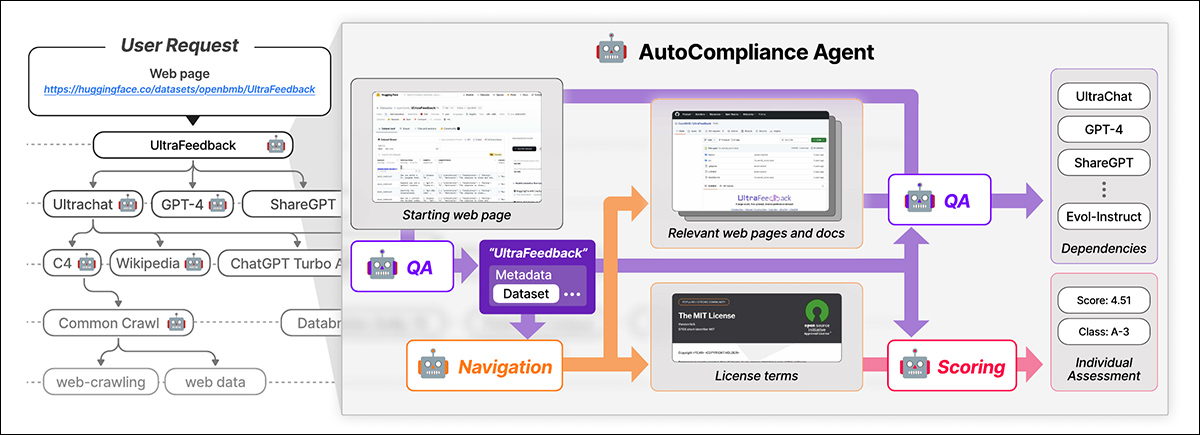
Autocompliance begint met een door de gebruiker geleverde webpagina. De AI extraheert belangrijke details, zoekopdrachten naar gerelateerde bronnen, identificeert licentievoorwaarden en afhankelijkheden en wijst een juridische risicoscore toe. Bron: https://arxiv.org/pdf/2503.02784
Deze modules worden aangedreven door verfijnde AI-modellen, waaronder de Exaone-3.5-32b-instructie Model, getraind op synthetische en door mensen gelabelde gegevens. Autocompliance gebruikt ook een database voor cachingresultaten om de efficiëntie te verbeteren.
Autocompliance begint met een door de gebruiker geleverde dataset-URL en behandelt deze als de root-entiteit, op zoek naar de licentievoorwaarden en afhankelijkheden en het recursief traceren van gekoppelde gegevenssets om een licentie-afhankelijkheidsgrafiek te bouwen. Zodra alle verbindingen zijn in kaart gebracht, berekent het nalevingsscores en wijst het risicoclassificaties toe.
Het data -compliance -raamwerk dat in het nieuwe werk wordt beschreven, identificeert verschillende† Entiteitstypen die betrokken zijn bij de Lifecycle van de gegevens, inclusief datasetsdie de kerninput vormen voor AI -training; Gegevensverwerkingssoftware en AI -modellendie worden gebruikt om de gegevens te transformeren en te gebruiken; En Platformserviceprovidersdie gegevensverwerking vergemakkelijken.
Het systeem beoordeelt holistisch juridische risico’s door deze verschillende entiteiten en hun onderlinge afhankelijkheden te overwegen en verder te gaan dan de rote -evaluatie van de licenties van de datasets om een breder ecosysteem op te nemen van de componenten die betrokken zijn bij AI -ontwikkeling.
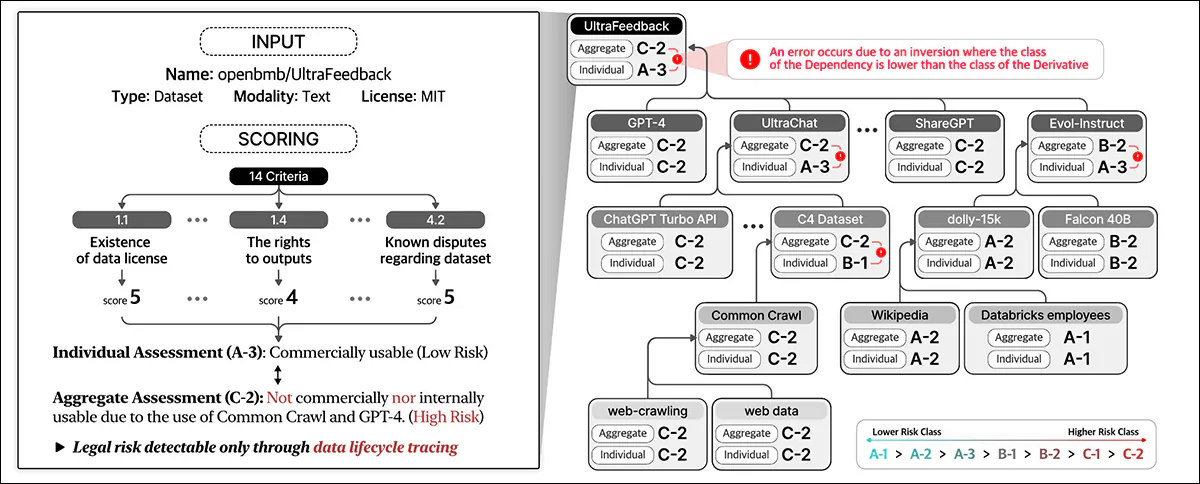
Gegevenscompliantie beoordeelt het juridische risico over de volledige levenscyclus van gegevens. Het wijst scores toe op basis van datasetgegevens en op 14 criteria, het classificeren van individuele entiteiten en het verzamelen van risico’s tussen afhankelijkheden.
Training en statistieken
De auteurs hebben de URL’s geëxtraheerd van de top 1.000 meest gedwaste datasets bij Hugging Face, willekeurig onderverdeeld 216 items om een testset te vormen.
Het ExaOne-model werd verfijnd op de aangepaste gegevensset van de auteurs, met de navigatiemodule en vraag-antwoordmodule met behulp van synthetische gegevens en de scoremodule met behulp van door mensen gelabelde gegevens.
Labels van de grond-waarheid werden gecreëerd door vijf juridische experts die minstens 31 uur in vergelijkbare taken zijn getraind. Deze menselijke experts identificeerden handmatig afhankelijkheden en licentievoorwaarden voor 216 testgevallen en hebben vervolgens hun bevindingen geaggregeerd en verfijnd door discussie.
Met het getrainde, menselijk gekalibreerde autocolliance-systeem getest tegen Chatgpt-4O en Pertlexity Pro, werden met name meer afhankelijkheden ontdekt binnen de licentievoorwaarden:
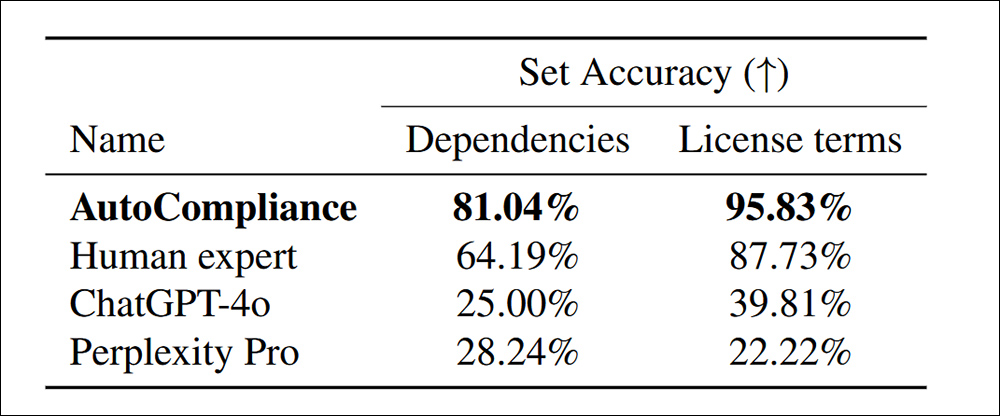
Nauwkeurigheid bij het identificeren van afhankelijkheden en licentievoorwaarden voor 216 evaluatiegegevenssets.
De krant stelt:
‘De autocompliance presteert aanzienlijk beter dan alle andere agenten en menselijke expert, waardoor een nauwkeurigheid van 81,04% en 95,83% in elke taak wordt bereikt. Zowel Chatgpt-4O als daarentegen tonen respectievelijk een relatief lage nauwkeurigheid voor respectievelijk bron- en licentietaken.
‘Deze resultaten benadrukken de superieure prestaties van de autocolliantie, wat de werkzaamheid ervan aantoont bij het omgaan met beide taken met opmerkelijke nauwkeurigheid, terwijl ze ook een substantiële prestatiekloof aangeven tussen AI-gebaseerde modellen en menselijke expert in deze domeinen.’
In termen van efficiëntie duurde de autocolliance -benadering slechts 53,1 seconden om te lopen, in tegenstelling tot 2.418 seconden voor equivalente menselijke evaluatie op dezelfde taken.
Verder kostte de evaluatierun $ 0,29 USD, vergeleken met $ 207 USD voor de menselijke experts. Er moet echter worden opgemerkt dat dit is gebaseerd op het huren van een GCP A2-Megagpu-16GPU-knooppunt maandelijks met een tarief van $ 14.225 per maand-wat betekent dat dit soort kostenefficiëntie voornamelijk gerelateerd is aan een grootschalige operatie.
Datasetonderzoek
Voor de analyse hebben de onderzoekers 3.612 datasets geselecteerd die de 3.000 meest gedaalde datasets combineren van het knuffelen van gezicht met 612 datasets uit de 2023 Initiatief voor gegevens herkomst.
De krant stelt:
‘Vanaf de 3.612 doelentiteiten hebben we in totaal 17.429 unieke entiteiten geïdentificeerd, waarbij 13.817 entiteiten verschenen als de directe of indirecte afhankelijkheden van de doelentiteiten.
‘Voor onze empirische analyse beschouwen we een entiteit en zijn licentie-afhankelijkheidsgrafiek als een enkele legerstructuur als de entiteit geen afhankelijkheden en een meerlagige structuur heeft als deze een of meer afhankelijkheden heeft.
‘Uit de 3.612 doeldatasets hadden 2.086 (57,8%) meerlagige structuren, terwijl de andere 1.526 (42,2%) een lagere structuren had zonder afhankelijkheden.’
Auteursrechtelijk beschermde datasets kunnen alleen worden herverdeeld met wettelijke autoriteit, die kan komen van een licentie, uitzonderingen van auteursrechtwetgeving of contractvoorwaarden. Ongeautoriseerde herverdeling kan leiden tot juridische gevolgen, inclusief inbreuk op het auteursrecht of contractovertredingen. Daarom is duidelijke identificatie van niet-naleving essentieel.
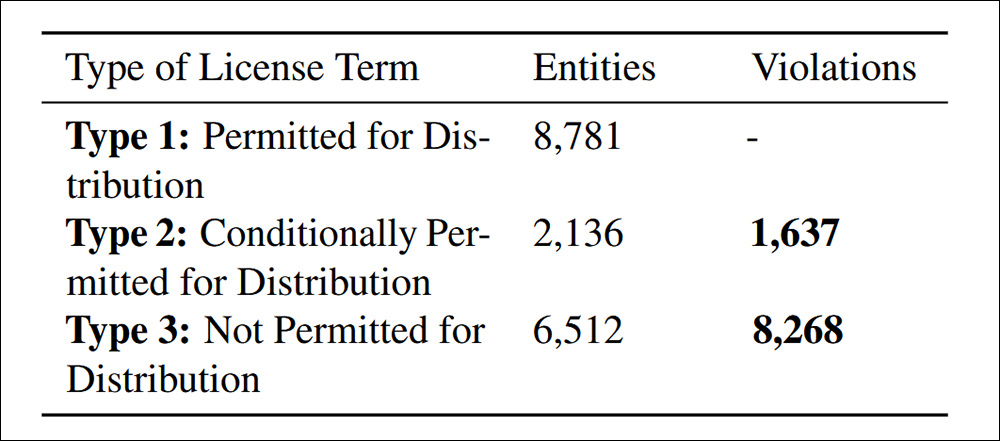
Distributieverschendingen gevonden onder het geciteerde criterium 4.4 van de krant. van gegevensconformiteit.
De studie vond 9.905 gevallen van niet-conforme datasetherverdeling, opgesplitst in twee categorieën: 83,5% was expliciet verboden onder licentievoorwaarden, waardoor herverdeling een duidelijke juridische overtreding was; en 16,5% betrof datasets met tegenstrijdige licentievoorwaarden, waarbij herverdeling in theorie was toegestaan, maar die niet voldeed aan de vereiste voorwaarden, waardoor stroomafwaarts juridisch risico werd gecreëerd.
De auteurs geven toe dat de in Nexus voorgestelde risicocriteria niet universeel zijn en kunnen variëren door jurisdictie en AI-toepassing, en dat toekomstige verbeteringen moeten gericht moeten zijn op het aanpassen aan veranderende wereldwijde voorschriften terwijl AI-gedreven juridische beoordeling verfijnt.
Conclusie
Dit is een prolix en grotendeels onvriendelijk papier, maar behandelt misschien wel de grootste vertragingsfactor in de huidige industrie -acceptatie van AI – de mogelijkheid dat blijkbaar ‘open’ gegevens later worden geclaimd door verschillende entiteiten, individuen en organisaties.
Onder DMCA kunnen overtredingen legaal massale boetes met zich meebrengen op een per geval basis. Waar overtredingen de miljoenen kunnen tegenkomen, zoals in de door de onderzoekers ontdekte gevallen, is de potentiële wettelijke aansprakelijkheid echt belangrijk.
Bovendien kunnen bedrijven waarvan kan worden bewezen dat ze kunnen hebben geprofiteerd van stroomopwaartse gegevens, niet (zoals gewoonlijk) Claim onwetendheid als excuus, althans in de invloedrijke Amerikaanse markt. Evenmin hebben ze momenteel realistische hulpmiddelen om de labyrintische implicaties te penetreren begraven in zogenaamd open-source dataset licentieovereenkomsten.
Het probleem bij het formuleren van een systeem zoals Nexus is dat het uitdagend genoeg zou zijn om het per toestand in de VS te kalibreren, of een per-natie in de EU; Het vooruitzicht om een echt wereldwijd kader te creëren (een soort ‘interpol voor dataset -herkomst’) wordt niet alleen ondermijnd door de conflicterende motieven van de verschillende betrokken regeringen, maar het feit dat zowel deze regeringen als de staat van hun huidige wetten in dit opzicht voortdurend veranderen.
* Mijn vervanging van hyperlinks voor de citaten van de auteurs.
† Zes typen worden voorgeschreven in de krant, maar de laatste twee zijn niet gedefinieerd.
Voor het eerst gepubliceerd vrijdag 7 maart 2025




